
Imagine you walk into an ice cream shop that only has one flavor.
“Where’s the cookie dough?” You ask.
“I’m sorry,” responds the shopkeeper. “We ran a test and found that 62% of our customers preferred chocolate to vanilla, so we implemented chocolate across the board.”
“Maybe we’ll test chocolate vs. cookie dough next month.”
“So…One scoop or two?”
This situation sounds too ridiculous to be true, but it’s exactly what happens every time you run an A/B test.
Why A/B testing is no longer enough
With decreasing attention spans and rising competition over limited users, marketers are constantly seeking ways to engage their users and increase profitability.
Typically, this comes in the form of identifying the most effective marketing strategies and optimizing user experiences, and A/B testing has long been the darling of most marketing strategies and tools for accomplishing these purposes.
A/B testing, the practice of comparing two versions of a web page or mobile app to see which one performs better, has been a mainstay in the world of digital marketing for years. However, as technology advances and data becomes more sophisticated, the limitations of A/B testing are becoming increasingly apparent.
A/B testing is an incredibly manual process, for which you need to perform the following steps:
Pick a goal: It’s on you to identify the metric that you want to improve, such as click-through rates or conversion rates, and set a clear objective for your A/B test.
Make a hypothesis: Formulate a hypothesis about why one variation of your website or message will perform better than another.
Design all of your different variations: Create two or more versions of your website or message that differ in one specific way.
Select your audience: You have to do this step very carefully or you could get some dangerously misleading results, so be sure to control variables you know could contribute a significant difference. (e.g. If mobile users generally tend to click less than desktop users, you should make sure each of your "random" groups contains an equal number of each type of user.)
Run your experiment: Randomly assign your treatments to each of your audiences and measure the performance of each variation against your objective. You have to be sure to run the experiment for a long enough time period to gather a sufficient amount of data and ensure that the results are statistically significant.
Analyze your results: Compare the performance of each variation and determine which version performed better based on your objective. Use statistical analysis to ensure that your results are reliable and not due to chance. If one variation significantly outperforms the others, you can implement that variation permanently on your website or app.
This process requires a considerable amount of time and resources to plan, execute, and analyze, which is why even the most adept teams can only afford to run a handful of A/B tests at a time.
Workload aside, with A/B testing, you can only test a limited number of variables at once, making it difficult to find the best combination of strategies. By design, the tests need to be siloed to a degree.
It’s also difficult to be reactive with A/B testing since the tests are so time-consuming to execute, analyze, and implement.
This is where reinforcement learning and bandit algorithms come in.
What are reinforcement learning/bandit algorithms?
Reinforcement learning and bandit algorithms are two machine learning techniques that are quickly emerging as superior alternatives to A/B testing.
Reinforcement learning is a machine learning technique that involves training an algorithm to make decisions based on rewards and punishments. In the context of mobile app and website optimization, reinforcement learning can be used to personalize the user experience by analyzing user behavior and making real-time decisions about what content to show them. By continuously learning and adapting to new data, reinforcement learning algorithms can deliver a personalized experience that is more likely to engage users and drive conversions.
Bandit algorithms, on the other hand, are a family of machine learning algorithms that are specifically designed for problems that involve balancing exploration (trying new things) with exploitation (exploiting what has worked well in the past). In the context of mobile app and website optimization, bandit algorithms can be used to deliver personalized content to users based on their past behavior while also testing new content to see if it performs better. This approach allows businesses to strike a balance between delivering a personalized experience and experimenting with new content to drive engagement and conversions.
Simply put, A/B testing is like a game of Battleship — you're blindly guessing where to place your shots.
Reinforcement learning and bandit algorithms are like playing chess - strategically testing and adjusting your moves based on data.
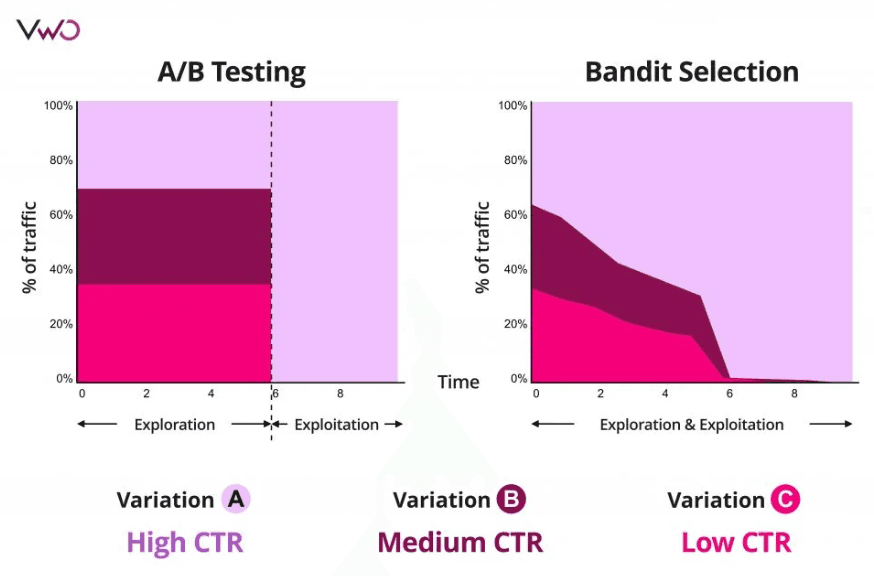
Why reinforcement learning and bandit algorithms are more effective than traditional A/B tests
Compared to A/B testing, reinforcement learning and bandit algorithms offer several advantages:
They can analyze more data than A/B testing, allowing for more accurate predictions about user behavior. Unlike A/B testing, reinforcement learning and bandit algorithms can also test multiple variables simultaneously, allowing you to quickly identify the best combination of strategies for your users and ultimately get better results in less time.
They learn continuously. A/B testing provides insights for a specific campaign or time period, but reinforcement learning and bandit algorithms continue to learn and optimize over time. As new data comes in, the system can adapt and improve its performance, providing ongoing benefits to your marketing efforts.
They can adapt to new data in real-time. As the system receives feedback and learns what works best, it can adjust on the fly, maximizing engagement and conversions in real-time. Reinforcement learning systems are more sensitive to changing seasons, significant macro/global events, and user preferences, which is especially important in today’s fast-paced digital landscape where timing and relevance are crucial to success.
They can deliver personalized experiences that are tailored to individual users, based on their unique, demonstrated behavior, preferences, and other data points. In addition to increasing key KPIs like engagement, retention, and conversions, this can help you build stronger relationships with customers and convert them into more valuable users over time.
Additionally, studying the output of your reinforcement learning and bandit algorithms can help you make data-driven decisions, ensuring that you're always staying ahead of your competition.
Reinforcement Learning Case Study: Engaging Delivery Drivers
Many rideshare and food delivery apps use SMS to help encourage their drivers to pick up shifts. Drivers are essentially the “supply” or the “product.” Without available drivers, the app has nothing to offer its users.
The challenge with SMS is that it’s costly and doesn’t scale well — Even with rough localization, the costs of sending every available driver an SMS about every available nearby shift would get unruly very quickly.
In this use case, reinforcement learning and bandit algorithms can be used to predict which drivers are more likely to pick up shifts based on a number of simultaneous factors including timing, distance to pick up or drop off point, the length of the trip, and even the weather conditions — much more than you could detect in a series of simple A/B tests.
Once the model learns the preferences of each of your individual drivers, you can apply this logic to your SMS distribution and save money and get much higher engagement while sending fewer overall messages.
How reinforcement learning and bandit algorithms save you time and effort
In addition to being more accurate and adaptable, reinforcement learning and bandit algorithms are also much less resource intensive than traditional A/B testing because they’re designed to optimize the user experience in real-time, without the need for extensive manual intervention or data analysis.
As we mentioned, with traditional A/B testing, teams must first design and set up two or more versions of a web page or message and then track user behavior over a period of time to determine which version is performing better. This process can be time-consuming and resource-intensive, requiring significant amounts of time and effort to set up and manage.
Reinforcement learning and bandit algorithms, on the other hand, are designed to operate in real-time, making them much more efficient and less resource-intensive—once these systems are set up and trained, they can continuously monitor user behavior and make decisions about content and experiences on the fly without the need for extensive manual intervention.
This efficiency is particularly valuable in industries like ecommerce, where even small improvements in conversion rates can have a significant impact on revenue. By using reinforcement learning and bandit algorithms to optimize the user experience more or less autonomously, businesses can continuously make small, incremental tweaks and improvements that add up over time without having to devote significant resources to manual testing and analysis.
Moreover, these algorithms allow marketing teams to learn faster from user data, enabling them to update recommendations and messages in real-time to keep up with ever-changing consumer behavior.
If reinforcement learning and bandit algorithms are so great, why don’t I ever hear about them?
Reinforcement learning and bandit algorithms aren’t uncommon. They are regularly used in a variety of fields and applications, ranging from healthcare, finance, dynamic pricing, and recommender systems, to influence maximization, information retrieval, dialog systems, anomaly detection, and telecommunications. They just haven’t been accessible.
One major obstacle is that reinforcement learning requires significant data infrastructure and technical expertise to implement. It involves training a model on a large data set, and then using that model to make predictions in real-time. This requires specialized hardware and software, as well as skilled data scientists and engineers to set up and maintain the system.
Big companies like Amazon, Netflix, Zillow, StichFix, and many others have been using them for years. It simply hasn’t been available to smaller companies.
Another challenge is that reinforcement learning is still a relatively new technology, and there is a shortage of experts who can implement and manage it effectively. The field of machine learning is evolving rapidly, and keeping up with the latest research and best practices can be a daunting task for many organizations.
There’s no question that it produces results. At this point, it’s just an implementation problem.
The way forward
While traditional A/B testing has been a staple in the world of digital marketing for years, it is becoming increasingly apparent that this method is not optimal in terms of accuracy, adaptability, or resource efficiency.
As the technology evolves, reinforcement learning and bandit algorithms are emerging as superior alternatives, delivering personalized experiences that are tailored to individual users and optimized in real-time.
With the ability to learn quickly from user data, these algorithms offer businesses the opportunity to continuously improve their user experience, drive engagement and conversions, and stay ahead of the competition.
To implement reinforcement learning and bandit algorithms into your marketing campaigns, you have two options.
The hard way
Gather all the data you can. clicks, app visits/website behavior, product views, product purchases. All of it.
Train the algorithm. Once you collect, clean and analyze your data, use it to train their algorithms by testing different messaging options and measuring their effectiveness in real-time.
As more data is collected and algorithms are refined, businesses can continuously optimize their SMS marketing campaigns to deliver better results.
The easy way
At Aampe, we’ve already built the infrastructure your company needs to implement a full reinforcement learning/bandit algorithm system for user messaging in less than a week.
Once you connect your event stream (CDP) and messaging provider (CPaaS), draft your messages and variants, and click “Start Sending,” you’ll have the full power of our reinforcement learning-based system continuously learning your users through your messaging and tailoring future messages based on the results to optimize your conversions.
If you want to stay in front of the cutting edge and stay ahead of your competition, reach out to us at hello@Aampe.com.











