

Aampe is a reinforcement learning agent that personalizes emails, web/push notifications, SMS and WhatsApp messages for users. Some of the data workloads within the agent are written in SQL that is executed on GCP’s BigQuery engine. We use this stack because it provides scalable computational capabilities, ML packages and a straightforward SQL interface.
To improve the learning algorithm, we experimented with replacing our current method for updating user propensities for a certain policy with a Bayesian inference step. The step uses one of the alternative parametrizations of a beta distribution. Which means that we will need to be able to draw from a beta distribution in SQL. While working on this, I discovered that drawing from the random distribution in SQL is a topic with very few well documented examples. So I’m writing about it here..
Step 1: How hard could it be?
BigQuery doesn’t have a beta distribution. It doesn’t have the capability to draw from any random distribution. So my first intuition was to take the definition of the beta distribution, write it in SQL, set the parameters using a CTA, draw a random number between 0 and 1 and compute the value of that function.
But it’s 2024, so I asked ChatGPT how it would do it:
Me: “How do you create random draws from a beta distribution in BigQuery?
ChatGPT:
Me thinking to myself: Right, so that clearly won’t work.
Do you see the problem in the code? ChatGPT draws two different x values for the presumed beta distribution PDF. I fixed this, cleaned up the query a little and sampled 1,000 values. And here’s the SQL code for doing that:
Thank you all, that’s a wrap 🎁 See you in the next post!
WRONG! 🔴
Let’s take a trusted implementation of drawing from a beta distribution using the same parameters and compare the results. I’ve used SciPy’s beta.rvs() in Python and here are two 100-bin histograms that will allow comparing the two drawn distributions.
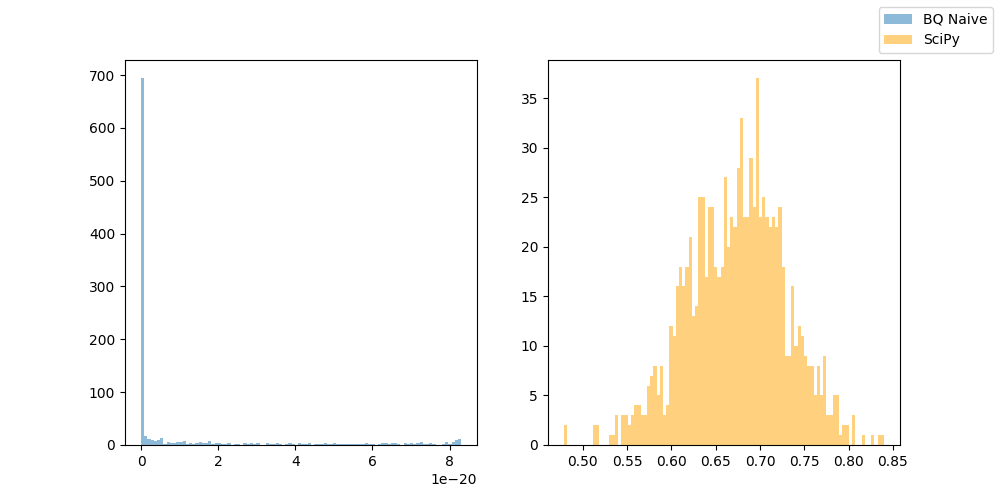
Well, it doesn’t take a magnifying glass to realize that the distributions are different. I went back the beta distribution definition and realized that it might be because the beta distribution also has a scaling constant which depends on the gamma function that I didn’t include in the calculation 🤦.
Problem: the gamma function does not have a closed-form expression, and BigQuery doesn’t provide an implementation that approximates it. So at this point I decided to switch to Python, a language that I’m more familiar with and will make my experimentation more efficient. The thinking was that if I nail it down in Python, I’ll be able to translate it to SQL. I would still need some way to approximate a gamma function, but one step at a time.
Step 2: What does drawing from a random distribution actually mean?
Let’s implement a manual draw from a beta distribution in Python, but now with the correct constant using SciPy’s gamma function:
Let’s examine the distribution using a 100-bin histogram again:
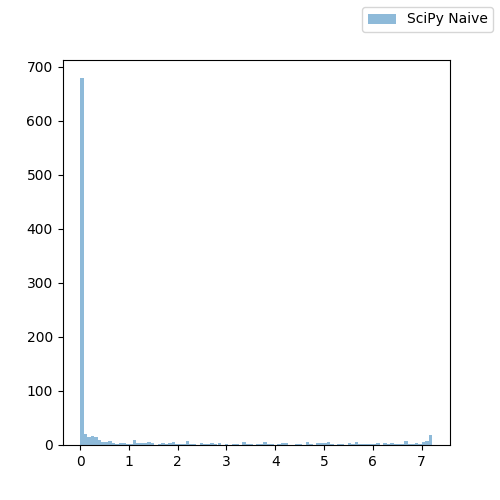
The first thing we notice is that the scale is now different, but the distribution still looks like the one drawn in BigQuery.
… something is wrong… it’s time for a short walk to think 🚶
…
After a short walk:
What does drawing from a random distribution actually mean? What I’ve implemented so far is randomly sampling from the beta probability density function (PDF) and it wasn’t working.
So I had to dig up some statistics classes.
Here are a couple of good refreshers on:
- Probability Density Functions (PDFs) and Cumulative Distribution Functions (CDFs) for Continuous Random Variables, and
- Generating Samples from Probability Distributions that I found helpful.
In short, the conclusion is that drawing from a random variable actually means sampling from the inverse cumulative distribution function (CDF), not from the probability density function (PDF) like I was doing so far.
Of course 🤦. My probability professor, who I just learned had passed away from illness in 2020, would have encouraged me to “review the basics” at this point..
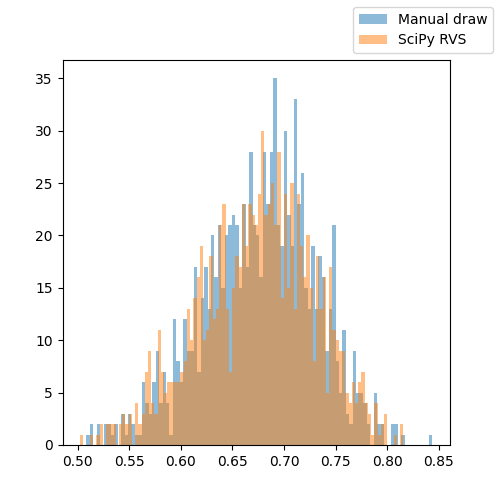
Ok. Let’s revisit the Python code, now drawing samples from the inverse CDF (which is also called the quantile function) of our beta distribution, and compare it to the distribution drawn using SciPy’s beta.rvs():
phew this looks much better:
Step 3: Back to SQL
Now that we’ve got drawing samples from a random variable straight, it’s time to move back to SQL. For the sake of simplicity, and because BigQuery does not readily come with an implementation of a Gamma function I'm going to draw from the logistic distribution (with parameters a=0 and b=1).
Let’s now compare the distributions of the three sampling methods:
- SciPy’s logistic.rvs
- Manually sampling the logistic distribution PDF in Python and drawing a random sample as per Step 2 above
- Doing the same in SQL
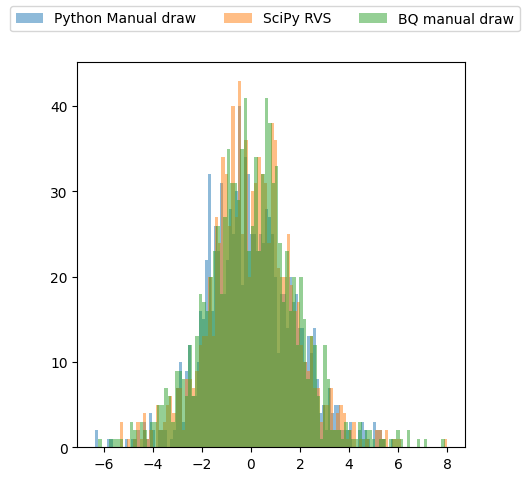
This looks like a success to me! 💪
This SQL code above samples from the logistic distribution, but it should work on any distribution where you are able to get a discrete representation of the PDF by sampling it at consistent intervals!



