
As our platform has to work with various data providers, CDPs, and many different companies with very different data lakes and schemas, it's actually more common for us to encounter messy data than anything else.
Here's our approach to cleaning up this data so it can be usable and actionable:
What is "messy" data?
"Messy data" can come in various forms. Here's what we see most commonly:
Empty data values
Missing data points
Unstructured form
Duplicate rows
Wrongly formatted columns
Incorrect data types
and more.
Also, this data can come in any of these formats:
CSV
JSON
Parquets
txt
Data tables
Avro
etc.
How we clean messy data
We're aware of all of these possible scenarios, but we don't have liberties to drastically change our customer's data formats, so we apply a structured minimal data model along with a data cleaner and translator to all the data we ingest.
This allows to ingest data in any format and any consistency to our system making it easy for customers to get onboarded with minimal effort.
Use as little as possible
The minimum data that we require for learning infrastructure consists of the following fields
user_id: An ID signifying the identifier of the user. (If it is PII we hash it.)
event_name: This can be anything like app_opened, added_to_cart, order_completed etc.
timestamp: The timestamp of the event - converted to UTC
metadata: This is any kind of metadata that is included with the event in whatever form. We convert this to a JSON string, so it can be unstructured and can contain any information present in the customer database.
Parallel Process
We employ a parallel-compute data processing pipeline when we ingest data from the customer into the system. This parallel processing pipeline performs all of the necessary data cleaning steps and then translation as outlined below:
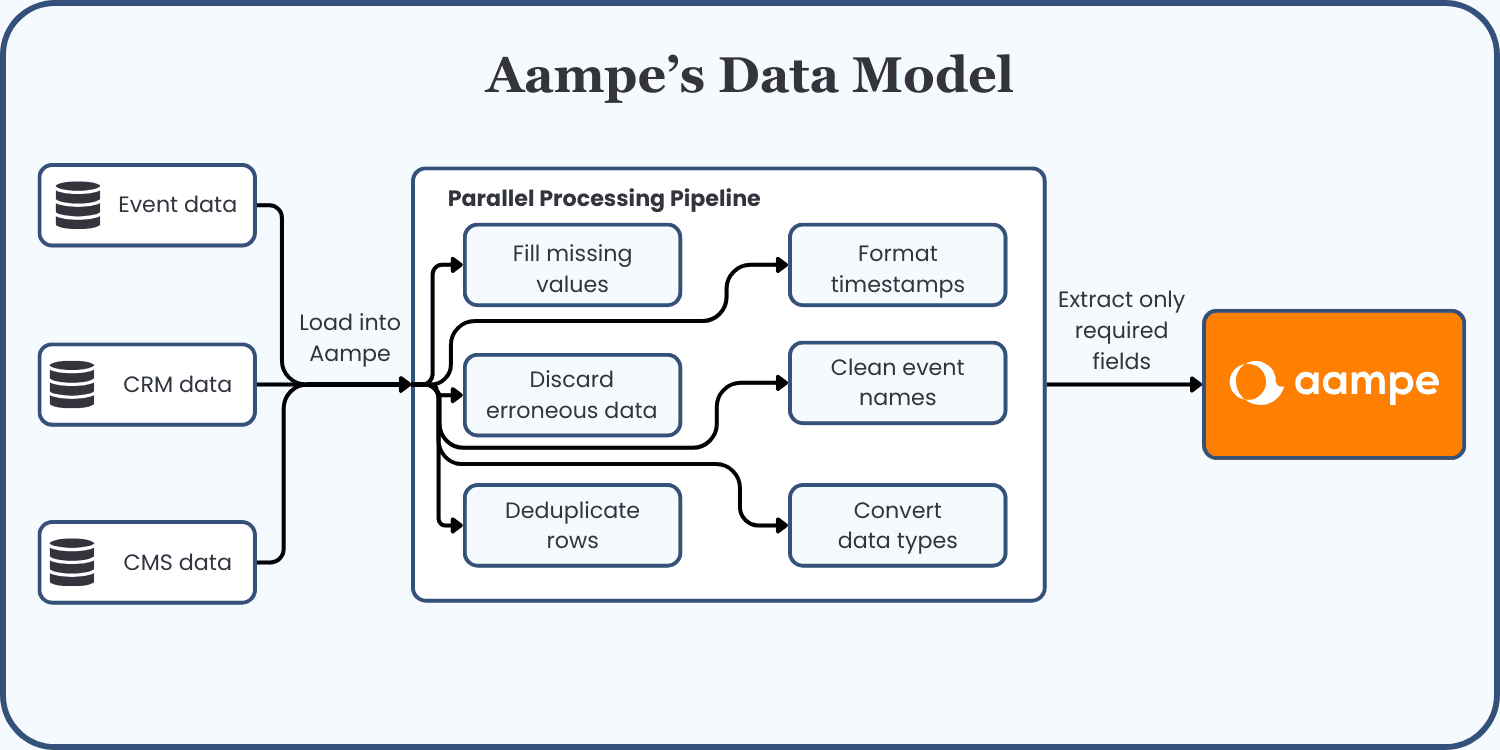
This allows us to be able to handle huge volumes of data, as it distributes data translation and cleaning across several compute machines and scales vertically whenever needed. Any other custom use cases to format data are also baked into the parallel pipeline.
Conclusion
By employing a minimal data model Aampe can work with any format of data the customer gives us and translate into the Aampe model with the required minimal fields. Any extra information allows us to add use cases, but the minimum data is used by our AI model to learn each user’s timing, copy, frequency and channel preferences to target efficiently.
To learn more, click the orange button, below.




